Removing MediaWiki from SPA: Cool URIs don't change
I run the website for SPA conference. This conference has been running for more than 20 years, and I’ve been the web admin since 2014. This is about one step in updating a 20-year-old legacy PHP site into something more modern: removing the integrated wiki. The story is in two parts and this part is about how I made sure links to the old wiki still worked. It involves many, many things I learned about .htaccess.
To read the other part of the story, about the actual changes I made to the site, see my previous post: Removing MediaWiki from SPA: changes to the site.
Getting rid of the wiki
The integrated wiki was mainly used for session outputs and user pages. I’ve described in my previous post how these are now handled on the main site.
When I’d made those changes, there was no longer any need for the wiki. However, there are lots of links to it from previous years, both of outputs and user pages, and Cool URIs don’t change.
By far the most time-consuming part of this work was redirecting old links to the new site. I thought it might be less work than my previous huge redirection of Direct.gov URLs when we launched GOV.UK, but it was close.
Saving the wiki as a static site
What I wanted to do was save the pages that already existed on the wiki as a static site. So the thing to do was spider the pages and save that. This is something I’m familiar with from /dev/fort, where we don’t have internet connectivity so we need to take the internet with us.
For a /dev/fort we use some Chef cookbooks but in this case, I only needed one command:
wget -m -k -p -nH -np \
http://www.spaconference.org/mediawiki/index.php?title=Main_Page
man wget if you want to know what the arguments are, but to save you a bit of time if you’re only mildly interested:
-m = mirror
-k = convert links
-p = download all page requisites
-nH = Disable generation of host-prefixed directories
-np = no parent; i.e. do not ascend to the parent directory
when retrieving recursively.
So then all I had to do was put the output of the spider into a directory called mediawiki, retire everything that was in the old mediawiki directory and job done, right? Well, not quite.
The URLs give no information about content
The first issue was that the web server didn’t know what to do with the files. Most web servers guess at the content type based on the file extension. The files in my static site have names like http://www.spaconference.org/mediawiki/index.php?title=BelbinTeamRolesInSoftwareDevelopment. Without a file extension, browsers will assume it’s binary.
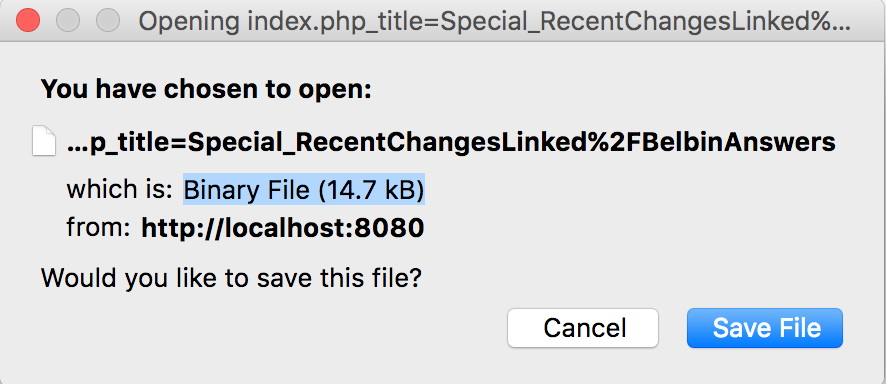
To solve this, I created a new .htaccess file in the mediawiki directory. I wanted to contain strange config needed for retaining the wiki information to the directory itself, rather than messing with the already somewhat complex .htaccess for the whole site.
I also took this opportunity to move the new MediaWiki folder into a public repo on GitHub. The rest of the SPA code is currently private (which is a story for another day) but there is no reason for this to be, and there is no reason for it to be part of the main SPA repo.
The first change to the .htaccess was to use Apache’s FilesMatch directive to tell the server that pages where the URL contains .php? should be returned as HTML.
<FilesMatch "\.php\?">
Header set Content-Type "text/html"
</FilesMatch>
? has a reserved meaning
The next issue was that all the saved MediaWiki file have names like index.php?title=Main_Page. But ? has a reserved meaning in the browser, to indicate a query string. So the browser will not be looking for a file with a name with a ? in it, it will be looking for what to do with a path of index.php and a query string of title=Main_Page.
So I needed to use Apache mod_rewrite to rewrite URLs so that index.php? would be replaced as index.php%3F. In that case, instead of trying to interpret the query string, Apache would look for the file.
This special requirement took me an extremely long time to work out how to do.
More detail of what it all means in the commit message but the answer was:
RewriteCond %{QUERY_STRING} (.+)
RewriteRule ^(index\.php)$ $1\%3F%1 [L]
Spending ages on CSS and JavaScript
I’d redirected the PHP pages in the two stages described above, first making the browser recognise the files were HTML, and then redirecting to the correct filename. So I tried to do the same with the JavaScript and CSS. I initially tried to add a FilesMatch directive to CSS files but it didn’t have the desired effect. I then tried with the JavaScript but got the same result. It kept saying that the content-type was text/html.

This also took me a long time to work out, but I eventually realised that this was because the redirect wasn’t in place – after all, it didn’t have index.php in the title so it wasn’t getting rewritten. The text/html was coming from Apache’s 300 (Multiple Choices) response, which was, of course, HTML.
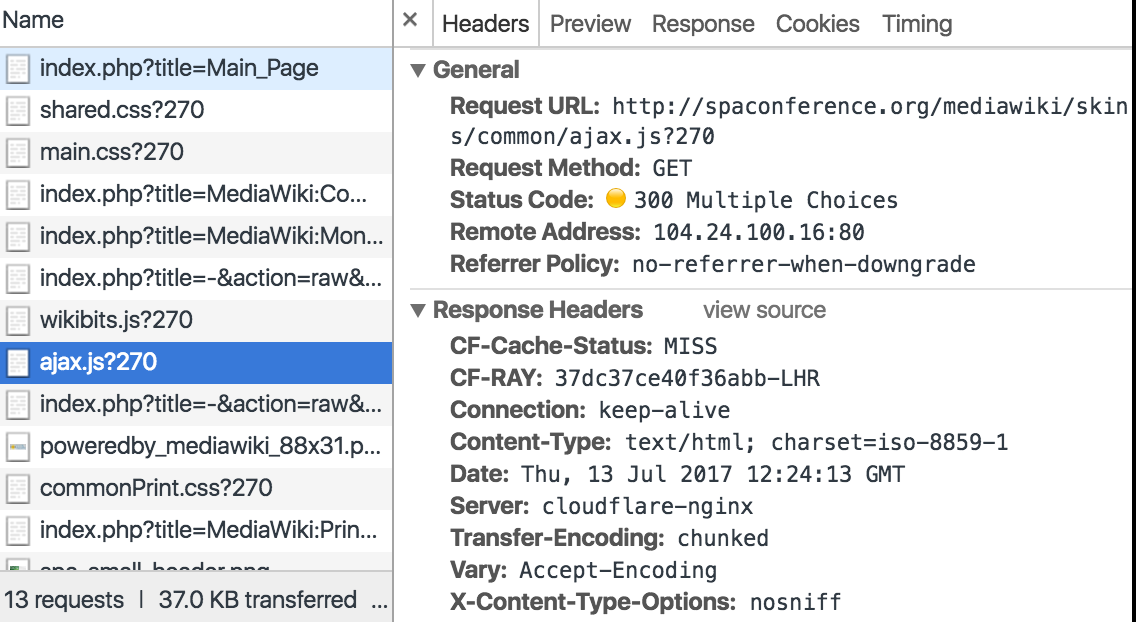
When I did both the redirect and the FilesMatch at the same time it had the desired effect.
There was an extra JavaScript file with a URL that would have required a whole new level of regexing – /index.php?title=-&action=raw&gen=js&useskin=monobook&270 – but the lack of this file doesn’t appear to have any observable effect apart from a console error so I have left it.
I could also probably tidy up the regexes so there isn’t one rewrite rule for each different file, but there doesn’t seem to be much point – it would only make it slightly harder to understand and introduce the possibility for error. It is not easy to understand .htaccess files as it is. If I planned for this one to get very long then it might be worth doing, but in this case it’s a finite piece of work: I don’t intend to be updating this directory once this move is finished.
The spider hadn’t grabbed everything
It was at this point that I discovered that wget had not grabbed all the files.
Earlier this year I had discovered that redirects had not been set up for one of the previous wikis (there were at least two before MediaWiki, to my knowledge). I had put a lot of redirects in place, and that meant I had a lot of test data that I could use to check links were working. But many were not.
I realised that wget had not downloaded all of the files because some were not linked to from within the wiki, so wget didn’t know about them. This was mainly user files, because the wiki didn’t know about all users; it was only the people.php script, which generated the ‘card index’ that knew about all users (more on that later).
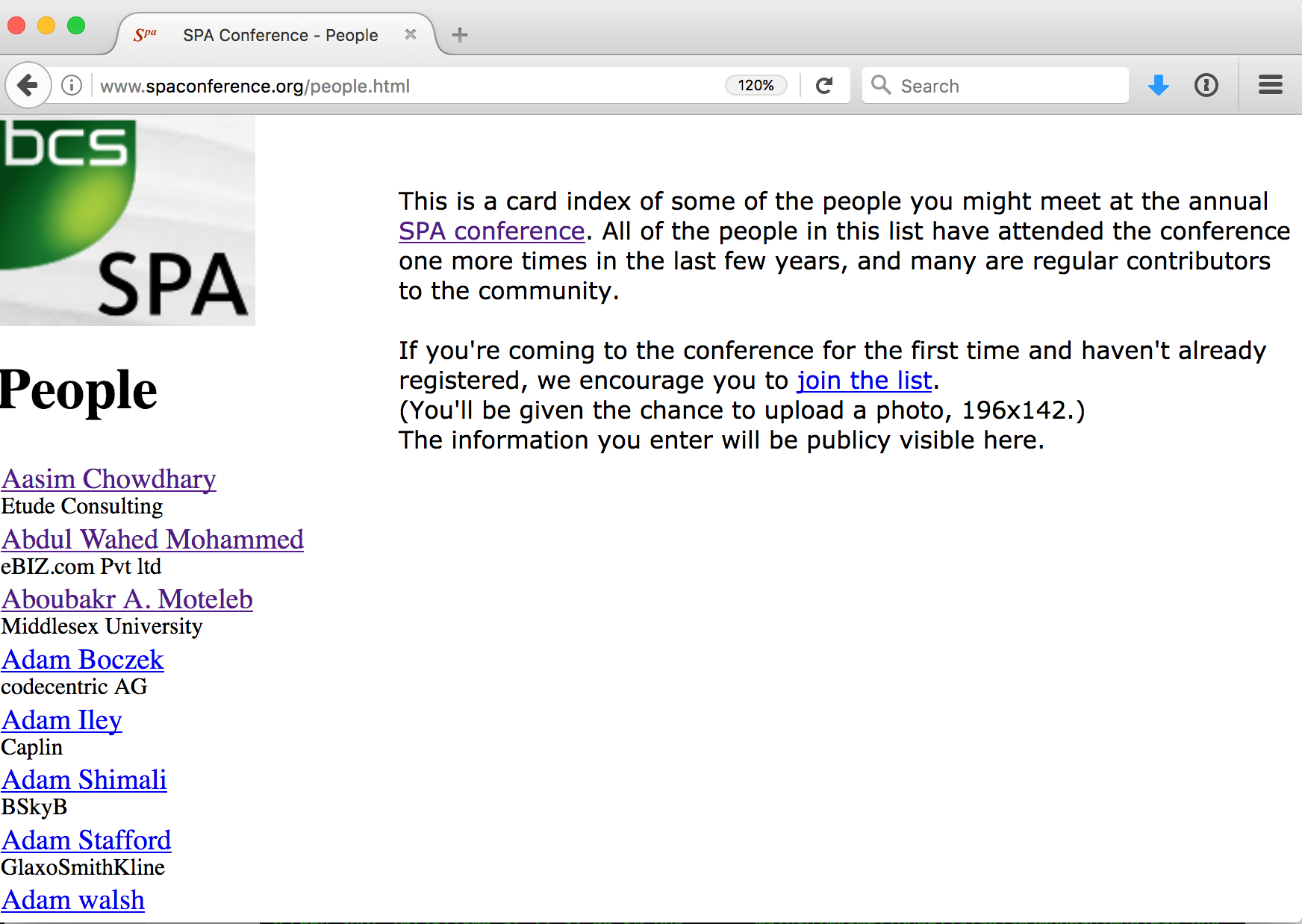
I could have crawled that page, but the point of retiring this content is not so much to back up all the data that was ever on the wiki (especially as many of the user pages were blank so were just their name and the wiki chrome), instead it is to preserve old links. So the user pages that I needed were ones that were linked to from previous programmes.
So I put the wiki back in place and crawled it again, this time starting from each of the programme pages between 2011 and 2016 (the years where MediaWiki was in operation and the programme linked out to users).
The command was almost the same as the above, except without the np flag – no parent. In this case, we did want the spider to go up to the parent directory so that it could then go across to the mediawiki directory to get the users.
This did mean that the spider crawled a lot more than we needed because it was grabbing everything linked to. However, it’s possible to put all the starting directories in one command, in which case wget doesn’t download the same resource twice. It’s also possible to avoid that by doing wget into the root of the site locally – whichever folder structure you’re in it builds entire folder structure from root, but I was doing it into a separate directory. I also used Amphetamine to stop my computer going to sleep, and directed STDERR to a file so I could check afterwards for 500s, 404s, etc.
wget -m -k -p -nH \
http://spaconference.org/spa2016/programme.html \
http://spaconference.org/spa2015/programme.html \
[...etc] 2> file.txt
I then copied the new output over the existing mediawiki directory and committed only the new files. There was no need to commit any changed files because the changes were just things like timestamps.
Redirecting all user pages
At this point, the static site contained all the pages from the wiki, and I just needed to create the redirects. Links from previous conferences to users are of the form http://spaconference.org/scripts/people.php?username={$USER} which redirected the user to the person’s wiki page, i.e. http://spaconference.org/mediawiki/index.php?title=User:{$username}. So the in order to be able to remove the people.php script, I just needed to put the redirect in the .htaccess:
RewriteCond %{QUERY_STRING} ^username\=(.+)$
RewriteRule ^scripts/people.php/?$ /mediawiki/index.php?title=User:%1 [R,L]
I then needed to make sure all the redirects worked.
I also needed to deal with the case where the page wasn’t there.
Dealing with missing pages
On the wiki, where there wasn’t a user you would get:
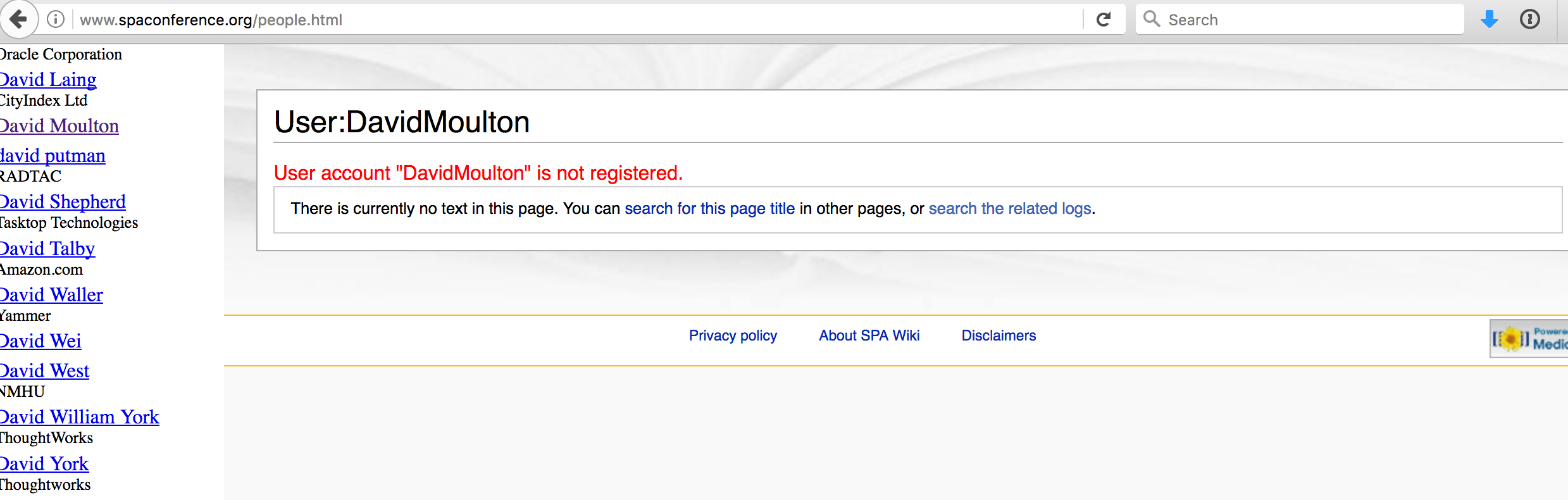
Not ideal, but now there is no MediaWiki framework around it, for a missing page it was even worse:
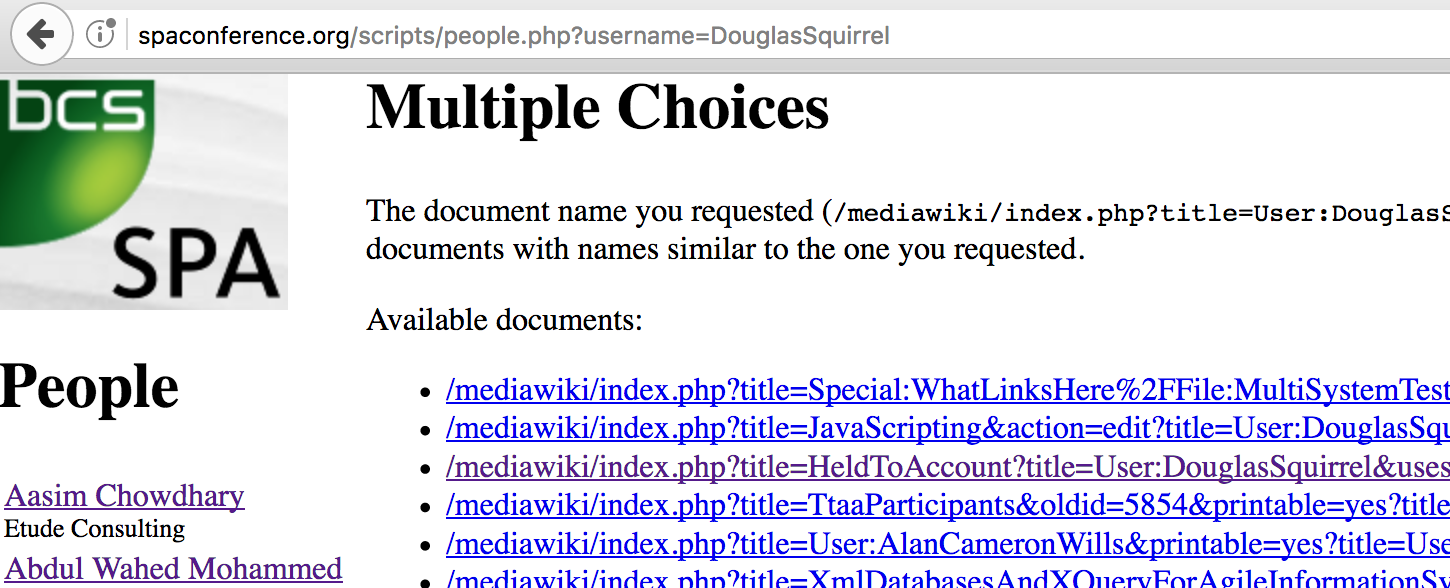
If there’s no page, I definitely don’t want that 300 result, I want a 404. But it took me a long time to figure out what the issue was. I went down a rabbithole about content negotiation and turning off MultiView without success, and then eventually by chance discovered that the second part of the error message (“However, we found documents with names similar to the one you requested”) also appears when Apache is attempting to use the hilariously named mod_speling.
Check spelling is useful for the main site because it allows URLs like http://spaconference.org/spa2018/organiser.html and http://spaconference.org/spa2018/Organisers.html to go to the right place.
However, for the wiki site we didn’t want it, so I turned it off for the mediawiki directory only.
CheckSpelling Off
This now returns a 404 if the exact URL can’t be found.
Dealing with pages that had always been missing
There was some extra MediaWiki chrome to deal with. For example, all the pages have an IP address at the top which is apparently a link to a user page for the IP address the user is editing from. However, when I ran the wget the site was behind CloudFlare, so in fact the IP addresses here are CloudFlare IPs. In any case, the user pages had nothing in them, so a 404 seems appropriate.
Login/create account on any page took you to the MySPA login page and then back to the page of the wiki you were on, through a URL something like http://www.spaconference.org/mediawiki/index.php?title=Special:UserLogin&returnto=User_talk:141.101.99.128 and some clever code that linked the wiki to the main conference site. Since it’s no longer possible to log into the wiki (as it is no longer a wiki) I also made this a 404.
I also created a 404 page. Previously, it had been the unstyled Apache 404; not a good look.
Linking to new user pages
Turning off CheckSpelling avoided lots of 300 errors, but it also meant that a lot of pages were missing because of the URLs. On the wiki, several of the links had extra query parameters. A really common one was &useskin=bio because it turned out the PHP pages that created the ‘card index’ added this parameter.
The people pages were linked up to the wiki via scripts/people.php. For example: http://spaconference.org/scripts/people.php?username=MarinaHaase. The people script passed that call through to a Smarty template, code below:
<html>
<head>
<title>SPA Conference - People</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<frameset cols="184,*" border=0>
<frame name="index" src="/people/index.html" marginwidth=0>
<frame name="person" src="/mediawiki/index.php?title=User:{$username}&useskin=bio" marginwidth=0>
</frameset>
<noframes>
<body bgcolor="#FFFFFF" text="#000000">
We're sorry - the SPA people page requires a browser that supports frames.<br>
<br>
<a href="index.html">Click here</a> to return to the conference site.
</body>
</noframes>
</html>
The template created a page made up of two frames, one being the ‘card index’, which was actually just a list of all users, and the other frame loading the user’s page from the wiki. In the example above, the frame would display /mediawiki/index.php?title=User:MarinaHaase&useskin=bio.
(Either that, or it said “We’re sorry - the SPA people page requires a browser that supports frames.”)
An interesting result of that was that if you did go to the wiki via a link like the one above and then choose someone else from the ‘card index’, the URL would remain the same.
However, it turned out that none of the stored files have &useskin=bio in their title, so this would lead to a 404 even when the page was present.
I solved this by adding a redirect to ignore all second query parameters.
RewriteCond %{QUERY_STRING} (.+)&(.+)
RewriteRule ^(index\.php)$ $1\%3F%1 [L]
This rule looks for all query strings that have two parameters and then discards the second one. (We still need the first one because it’s the user’s name, e.g. ?title=User:MarinaHaase.)
Removing all the people files
With all these redirects in place, I could now remove all the PHP files that connected to the wiki, e.g. the Smarty template shown above.
I could also remove all the MediaWiki tables from the database – there were 49 MediaWiki tables in total.
This was extremely satisfying.
That wasn’t the end of it
Before MediaWiki was the wiki, there were (at least) two other wikis for the SPA site, and when they were replaced, there were redirects to the new site in the .htaccess. However, they just redirected to /mediawiki/, relying on index.php to do the right thing. For example:
RewriteRule ^cgi-bin/wiki.pl/?$ /mediawiki/ [L]
However, there isn’t an index.php any more, just a bunch of flat HTML files.
I updated all those redirects to the main wiki page, for example:
RewriteRule ^scripts/wiki$ /mediawiki/index.php?title=Main_Page [R,L]
I needed to add the [R] flag to redirect the URL. Without a redirect, the page doesn’t get the CSS or other assets as they are referenced using relative paths.
How do you send a 403 to a 404?
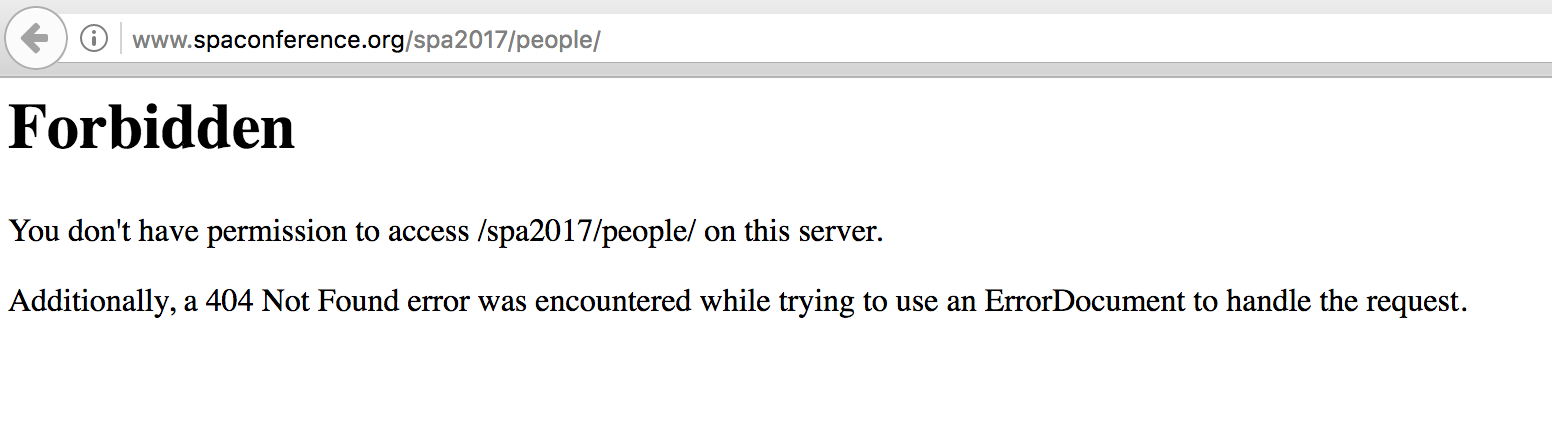
These changes meant that there were a few more pages where Apache returned a 403 Forbidden. In particular, http://www.spaconference.org/mediawiki/ and http://spaconference.org/people/ both no longer have an index page to do the right thingwhich resulted in a 403: ‘You don’t have permission to access /mediawiki/ on this server.’
Firstly, this was again an unstyled Apache response page, and secondly, it makes it sound more interesting than it is. It’s not that there’s something cool there you can’t see, it’s just “hey everyone! We use Apache!”.
My initial plan was to redirect the 403 to a 404 (This is an acceptable way to handle a 403, according to RFC2616.) However, I could not work out how. One of the problems with Apache is that it’s very hard to Google for help, as it’s been in use for a very long time, so the internet is full of people asking questions and giving answers, many of whom do not have a clue. Much Googling and RTFMing led me nowhere. In desperation I even tried a suggestion to replace the 403 error document with a 404, which led to the worst of both worlds:
As an interim measure, I just returned the 404 pages for a 403 response, which is suboptimal but fine from most users’ perspective.
ErrorDocument 403 /404.php
What are users trying to do?
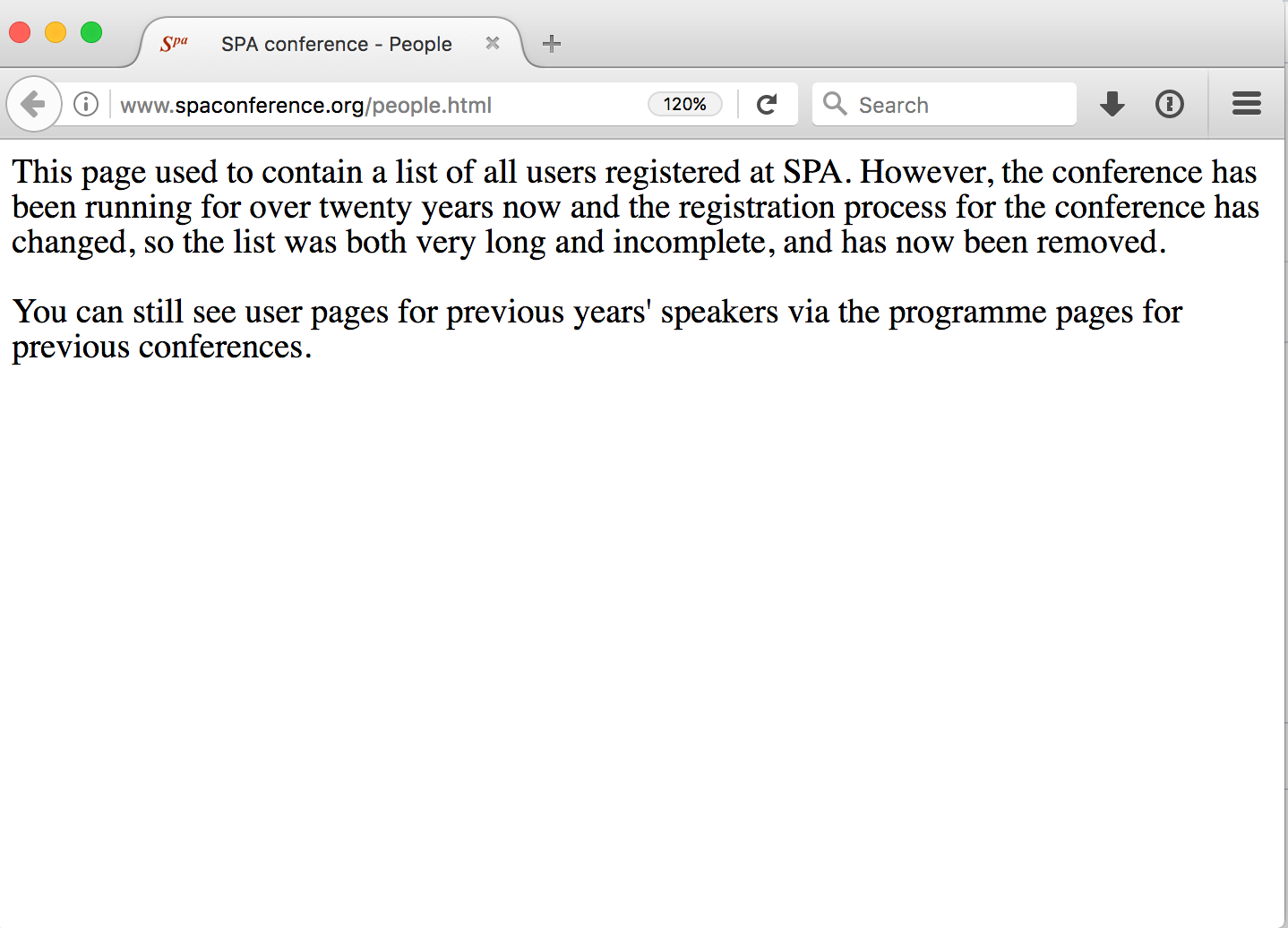
When users are trying to access /people/, they are probably trying to find out whether there is a list of all people there. So my first plan here was for people.html to have some text explaining what had happened. Here is this, unstyled (so with no SPA conference chrome around it).
However, even styled, this would have been no use at all.
In addition, because the disabling of CheckSpelling is in the /mediawiki/ directory not at the top level, http://www.spaconference.org/people/ is a 300, and the option it offers is http://www.spaconference.org/people.html/, which is a 404.
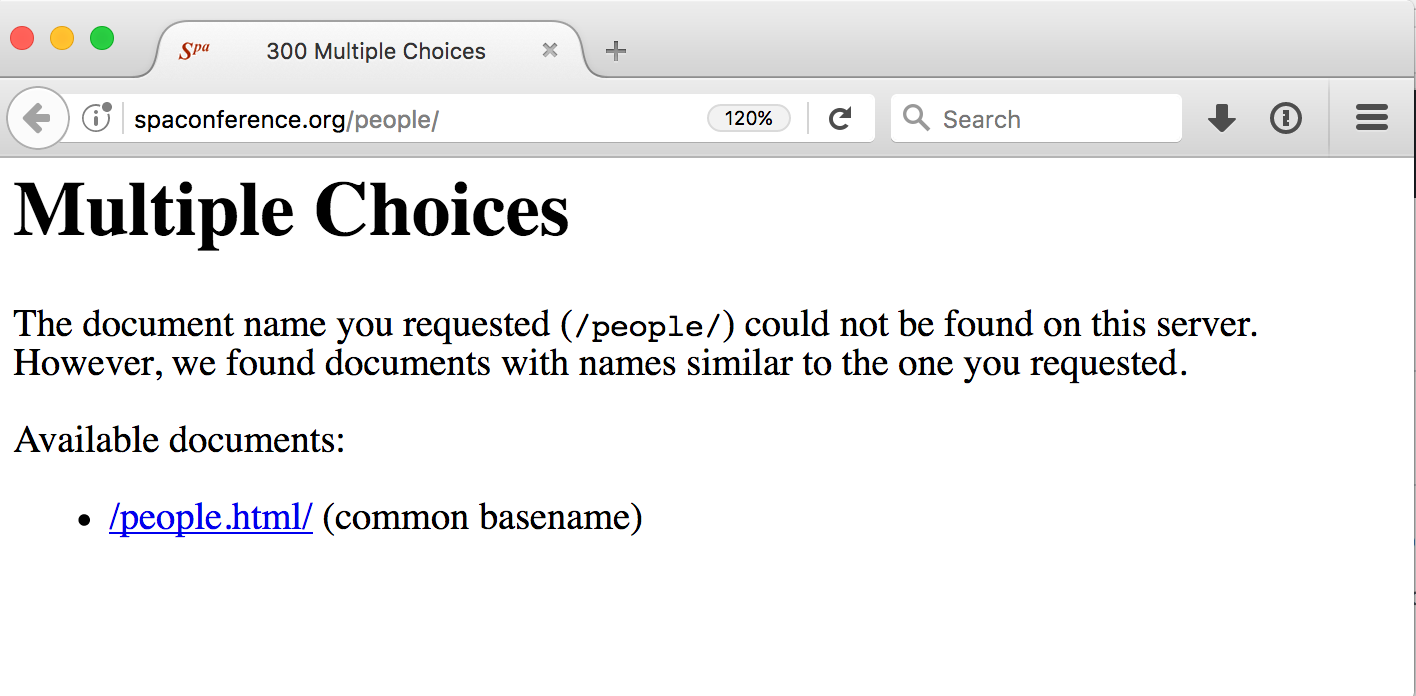
In summary, this was a terrible idea.
So I reconsidered the 403 to 404 approach and decided to redirect both of /mediawiki/ and /people/ the wiki home page. In the case of /people/ this is not really what they want either, but there is no longer a list of all SPA people and this will give them something.
This was straightforward for /people/.
RewriteCond %{QUERY_STRING} ^$
RewriteRule ^people/?(\.html)?$ /mediawiki/index.php?title=Main_Page [R,L]
In the case of http://www.spaconference.org/mediawiki/ it was slightly more interesting. /mediawiki to /mediawiki/ was already a 301 because of CheckSpelling, and if I put an index.html in the mediawiki directory then it would redirect to that, but I couldn’t use a ^$ redirect. I eventually figured out that this was because there is actually a directory there.
I found that if I put in a Redirect rather than a RewriteRule this worked, e.g.:
Redirect 302 /mediawiki/index.html http://www.spaconference.org/mediawiki/index.php?title=Main_Page`
(index.html doesn’t need to exist for this redirect to work)
However, then I realised that this work shouldn’t be done in that directory and in fact it’s a feature of the mediawiki folder that it doesn’t have an index.html and its homepage is actually the oddly titled index.php?title=Main_Page, so I deleted the Redirect and did the work in the mediawiki .htaccess instead:
RewriteCond %{QUERY_STRING} ^$
RewriteRule ^$ /mediawiki/index.php?title=Main_Page [R,L]
This solves the 403 to 404 issue. But I’m still interested if you can tell me how to redirect 403s to 404s correctly in Apache.
And that is the end of it, I think…
And I think we’re done. MediaWiki has been removed, but all the old outputs and information are preserved at the same URLs. Please do let me know if you spot any issues.
This was a lot of work but it was really fun and I learned far more about .htaccess than I’d ever intended to. I’m happy it’s moved me one step closer to bringing the SPA site up to date.
If you’d like to be notified when I publish a new post, and possibly receive occasional announcements, sign up to my mailing list: