No next Next
Last week, I wrote about how we worked out our tech strategy for FT.com. In this post I talk about the strategy itself: No next Next. And also about the Sugababes.
The launch of “Next” hugely improved the user experience
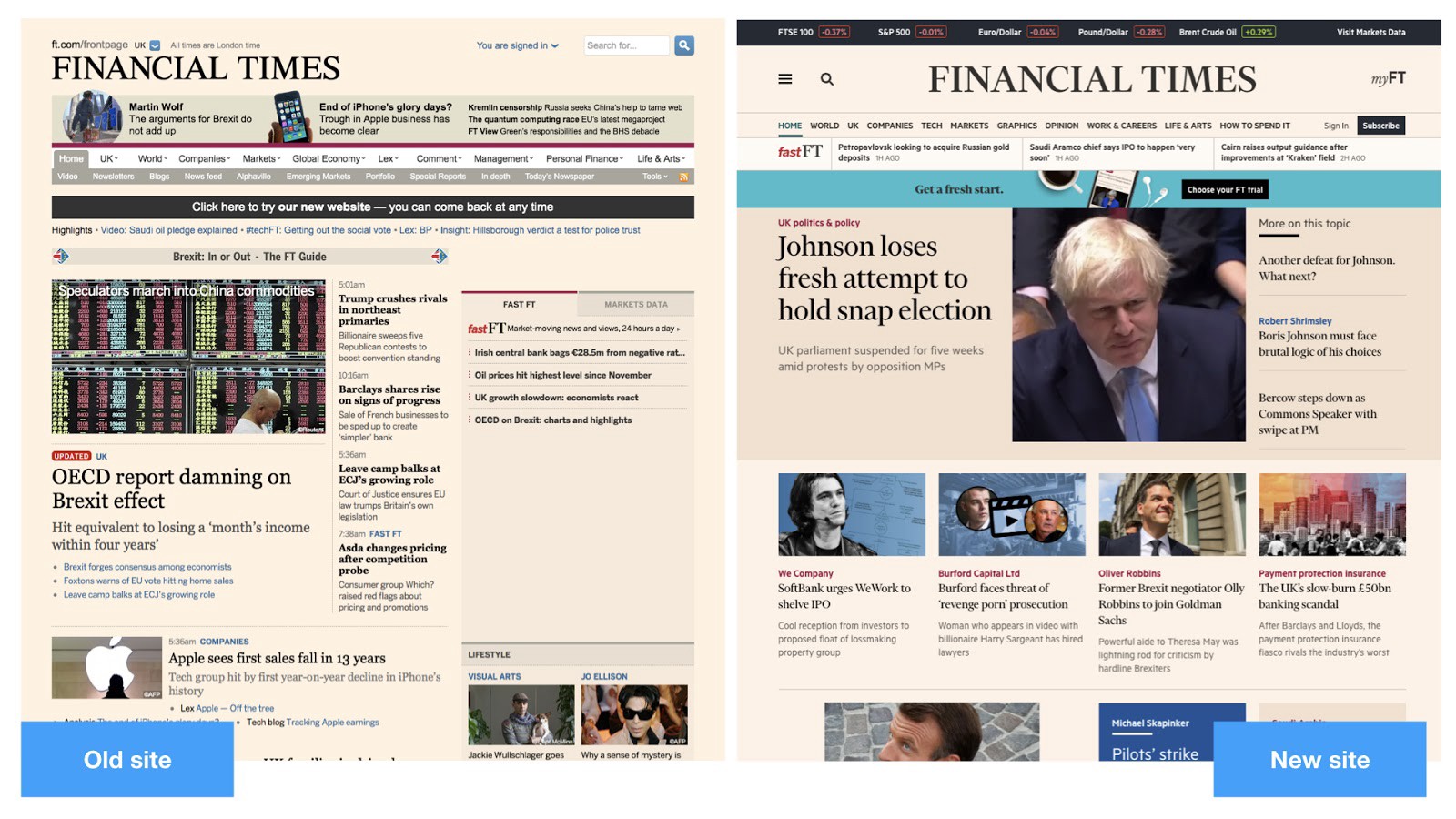
In October 2016, we replaced the old FT.com site with a new site, which we called “Next”.
The previous site didn’t have one team in charge of the whole; parts were owned by different parts of the business, meaning it was very hard to create a consistent user experience, keep it secure, or iterate quickly. Next is owned by one team which allows us to take a coherent approach to continuously improving the tech and customer experience.
The new site is built on a microservices architecture, ships hundreds of times a week and A/B tests everything. It is much faster than the old site and we demonstrated that this directly impacted revenue. It is much better designed, and our subscribers now come back more frequently and read more articles when they do. Earlier this year, we hit one million subscribers, a year ahead of our goal to do so.
But we don’t want to have to do it again
Building Next to replace the previous FT.com site took took two years and cost in the order of magnitude of £10m. Building it also meant that we had very limited capacity to change the old site while that work was in progress, so as well as financial costs it also had opportunity costs.
So we need to make sure we make the most of that investment. In order to do that, we need to steer it so that we don’t make the same mistakes we made with the old site.
No next Next
In a phrase, our vision for FT.com is No next ‘Next’.
We must make sure that the product and the underlying technology do not drift so far off course that we have to rebuild FT.com again in a few years, spending entirely avoidable time and money.
Instead, we want our tech to be sustainable, supportable, and operationally reliable, and we want it to be simple enough for new starters to get to grips with.
We don’t want to spend time grappling with complex technology, we want to spend our efforts on adding new features, innovating, and continuously improving the subscriber experience and value that the FT brings.
The Ship of Theseus and the Sugababes
If we want to make FT.com, the mobile apps, and other FT digital products sustainable for the long term rather than having to rebuild from scratch every few years, we will need to replace parts of it while it is in flight.
While talking about this we came up with a few analogies. The Ship of Theseus, rebuilt piece by piece while at sea. Trigger sees his broom as the same broom, despite the handle and head each being replaced a number of times. Or if those analogies don’t work for you, we could use the one that clicked it into place for our CTO, the Sugababes, where the final line-up contained none of the original members.
Whether or not you think the final line-up of the Sugababes is really the Sugababes, that’s the approach we need to take with FT.com and our customer products to make them sustainable over the long term.
Replacing the first band member is already increasing performance
In my previous post on building a tech strategy, I mentioned one way of finding out where to focus is asking engineers what code they feel afraid to touch. Through this method, we found that the package that manages the assets for FT.com hadn’t been worked on since the beginning of the Next project.
It performs multiple frontend services for FT.com, including building and loading client-side code, configuring and loading templates, as well as tracking, ads configuration and a lot more. It was tightly coupled to technical decisions made four years ago, and complicated. The current team did not feel confident making changes.
We put together a small team to update it, and they have now built a new service that splits all of this functionality into a set of loosely coupled, individually documented, and tested packages. The changes the team has made mean that any of our engineers can now confidently make contributions to this critical part of how we deliver the website.
It has also had an impact on the performance of the site. The team are currently migrating all of the FT.com services to the new packages, and each services that has been migrated shows decreases in the Time To Interactive of between 30% and 70%. This benefits users and also has an impact on revenue.
Communicating to the team and the rest of the business
One of the purposes of a strategy is to give focus, so we identified the highest priority areas to get us back on track. The first thing we worked on was communication.
It’s all about communication. You can have the best vision and strategy in the world but if no-one knows about it it is not going to get you very far.
We have three main audiences for the tech strategy:
- Engineers working in our team, who need to know what the strategy is and what the priorities are so they can make sure they are working on the right things and can get involved with wider strategic work.
- People outside of the team, so that they know what our focus is, how it will impact on their own priorities, and how to influence it.
- Senior people in the business, for example the board, who need to know that by doing a little, often, we will not need to suddenly request another huge multi-year investment to rebuild the site again.

Communicating the tech strategy and priorities
When we started working on the tech strategy we realised that there were communication channels missing so we had to fix that first. We also did some research into how people would like to receive the information.
We now do the following:
- In our monthly full team meeting, for all disciplines, we give a 3 minute update on our progress on the tech strategy.
- I give a quarterly tech talk, open to anyone, about our progress against the tech strategy: what we’ve done and what we’re doing next.
- We have a page about the tech strategy on our engineering wiki which we keep updated. Our wiki is in a private GitHub repo which means only people who have a GitHub license can see it, so we now run a nightly job that publishes it to a Heroku app that anyone at the FT can access.
- Our team has a monthly newsletter, sent to anyone in the business who is interested, and we update that with the progress on the tech strategy.
- When we have ad hoc updates about the tech strategy we email the team mailing list, and we always put [Tech Strategy] in the subject line so people can add filters (to make sure they never miss an update, of course!)
- Finally, we are blogging about what we are working on, so you can expect to read more about it here!
Refreshing and communicating our technical principles
Tech principles are a high impact area to focus on because if they are well known and adhered to, that’s a way to affect everyone’s behaviour and help people move in the same direction.
When I joined the FT I found that there were technical principles, but there were four or five slightly different versions in different places, many of them in slide decks from presentations, and none of them actively used.
We’ve now refreshed our tech principles and publicised them. We’ve even made posters! Matt Hinchliffe has written a great blog post with more detail about that here.

Making our out of hours process sustainable
The number of production outages for FT.com and the apps is very low, but occasionally we do get called out of hours to handle incidents. The team on the out of hours support rota are very responsive and deal with issues quickly and well. However, because our tech has grown more complex over time, it’s hard to get people — especially new starters — to join the out of hours rota.
Part of the solution to this involves doing the hard work to make the tech simpler. But there are other ways to help with this. One important thing is to make sure things you might be called up to deal with at 3am are well documented, and to get our most crucial systems up to a good standard we ran a Documentation Day, which Jen Johnson has written a great blog post about here.
We’ve also started running workshops to train people in dealing with out of hours incidents, which have really improved people’s confidence in being on the support rota. We will talk more about our progress on improving out of hours as we go.
Simplifying our tech to help us focus on growth
When systems get too complex, they become harder to support. It takes more time to identify and fix bugs, it is harder to spot potential security flaws, and engineers spend more time digging through code to try and understand it than they do on adding new features and improving the customer experience.
As the second law of thermodynamics states, everything tends towards entropy, so we have to actively work to fight this and keep our systems simple and high quality.
The effort we put into this pays off in reducing bugs and outages, increasing security, and making our technology easier to understand, meaning engineers can more easily work across the stack and spend their time on delivering things that add value to customers and to the business.
Measuring the simplicity of our systems
In order to reduce system complexity, it is very helpful to be able to measure it. Measurement will show us the most complex areas to tackle first, and when we start making improvements, we will be able to track our progress against the original complexity. Having a complexity measure is also important in communicating to people outside of engineering which areas need attention.
At the moment we are looking at visualising all our services and packages to indicate how well-maintained they are (for example, how frequently they are updated, how many open pull requests they have, etc). Later we will look at code complexity and other measures.
Our goal is to have an overview of our systems’ health that is meaningful to people outside engineering.
Clarifying our architecture
We have multiple teams working on microservices who are empowered to make technical decisions.
However, one of the common problems of the difficult teenage years is that without a clear technical vision, the teams can get out of alignment with each other. Different teams can make small technical decisions that ultimately lead to conflicting or unclear architectural changes.
We are doing a piece of work firstly to clarify our current architecture and clearly identify pain points and conflicts, and then to work on decision-making. We want to make it possible for tech leads to make architectural decisions that are consistent with other teams’ technical decisions, without imposing too much process on the decision-making.
Joining up FT.com and the mobile apps
When FT.com was rewritten, the team intentionally left the apps out of the rewrite so as not to take on too much at once, so “Next FT” is only the website, not the mobile apps. However, the team have been working hard since then on improving the apps and making sure features that are on the website are also on the apps, and vice versa.
The apps are a crucial part of our product, because in a modern news organisation we need to offer users many ways to consume our content, and it’s important to offer different things for different user needs. In addition, people who use the FT app tend to be very engaged with the FT, so there is a lot of value in improving their experience.
Because the apps were not in the Next rewrite, the app technology is out of step with the FT.com tech, and some of the underlying technology is now quite dated. We have been doing foundational work to bring the website development and app development closer together, so we can make use of the FT.com stack.
Once we’ve finished that we will be able to move much faster on the apps and do more exciting and ambitious work to add features for our highly engaged users.
More to come!
We will continue sharing our journey towards making our product more sustainable, and we’d love to hear your thoughts and experiences.
And if you are interested in joining us on this journey, we are hiring!
This post originally appeared on the FT Product & Technology blog.
If you’d like to be notified when I publish a new post, and possibly receive occasional announcements, sign up to my mailing list: