The CAP Theorem and MongoDB
This week I learned some things about MongoDB. One of them was about how it fits in with the CAP theorem.
They say a picture is worth a thousand words, and I think this diagram from my excellent new colleague Mat Wall while he was explaining it to me says everything:
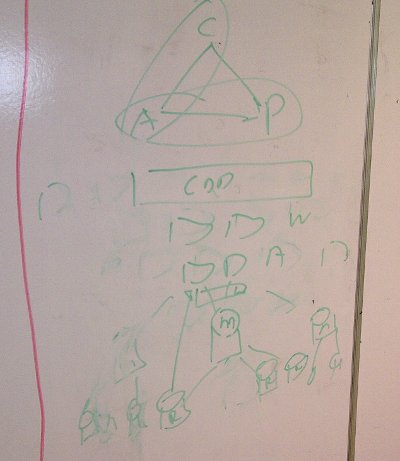
Over and out.
OK, perhaps I can offer a tiny bit of exposition.
The CAP Theorem is: where C is consistency, A is availability, and P is partition tolerance, you can't have a system that has all three. (It gets to be called a theorem because it has been formally proved.)
Roughly speaking:
- Consistency means that when two users access the system at the same time they should see the same data.
- Availability means up 24/7 and responds in a reasonable time.
- Partition Tolerance means if part of the system fails, it is possible for the system as a whole to continue functioning.
If you have a web app backed by a SQL database, most likely, it is CA.
It is C because it's transaction-based. So when you update the database, everything stops until you've finished. So anything reading from the database will get the same data.
It can be A, but it won't be P because SQL databases tend to run on single nodes.
If you want your application to be P, according to the CAP theorem, you have to sacrifice either A or C.
With MongoDB, in order to gain P, you sacrifice C. There are various ways to set it up, but in our application we have one master database, that all writes go to, and several secondaries (as can be seen from the diagram: M is the Master, the Rs are the secondaries – also called replicas, or slaves). Reads may come from the secondaries. So it is possibly that one or more of the secondary nodes could be disconnected from the application by some kind of network failure, but the application will not fall over because the read requests will just go to another node. Hence P.
The reason this sacrifices C is because the writes go to the master, and then take some time to filter out to all the secondaries. So C is not completely sacrificed – there is just a possibility that there may be some delay. We are not allowing a situation where the secondaries are permanently out of synch with the master – there is "eventual consistency".
So you might use this in applications where, for example, you are offering the latest news story. If User A gets the latest news 10 seconds earlier than User B, this doesn't really matter. Of course, if it was a day later, then that would be a problem. The failure case of C is just around the time of the write and you want to keep that window of consistency small.
There is also a concept of durability, which you can also be flexible with.
Take the following two lines of pseudocode:
1. insert into table UNIVERSAL_TRUTHS (name, characteristic) values ('Anna', 'is awesome')
2. select characteristic from UNIVERSAL_TRUTHS where name = 'Anna'
What we're saying when we sacrifice consistency is, if I run these two lines on the same node then when I run line 2, I can be sure it will return 'is awesome'. However, if I run line 2 on a different node, I can't be sure it's in already. It will still be "eventually consistent" so if I run it later (and it hasn't been changed again in the interim) it will at some point return the correct data.
However, you can also configure MongoDB to be flexible about durability. This is where, if you run the two lines of code on the
If you’d like to be notified when I publish a new post, and possibly receive occasional announcements, sign up to my mailing list: